We recently had a problem with literals having the same value but different datatypes. So I tried to reconstruct it. What I stumpled upon there surprised me:
# Insert data of different datatypes:
INSERT DATA { GRAPH <http://test.org/> {
<http://test.org/> <http://test.org/plain5> 5 ;
<http://test.org/long5> "5"^^xsd:long ;
<http://test.org/int5> "5"^^xsd:int ;
<http://test.org/integer5> "5"^^xsd:integer ;
<http://test.org/short5> "5"^^xsd:short ;
<http://test.org/nonNegativeInteger5> "5"^^xsd:nonNegativeInteger ;
<http://test.org/unsignedLong5> "5"^^xsd:unsignedLong ;
<http://test.org/unsignedInt5> "5"^^xsd:unsignedInt ;
<http://test.org/unsignedShort5> "5"^^xsd:unsignedShort ;
<http://test.org/positiveInteger5> "5"^^xsd:positiveInteger .
}}
# Select the values with datatype
SELECT ?p ?o (DATATYPE(?o) AS ?dt) FROM <http://test.org/> {
<http://test.org/> ?p ?o
}
# The result is all xsd:integer (export is the same)
| p | o | dt |
| http://test.org/plain5 | 5 | xsd:integer |
| http://test.org/long5 | 5 | xsd:integer |
| http://test.org/int5 | 5 | xsd:integer |
| http://test.org/integer5 | 5 | xsd:integer |
| http://test.org/short5 | 5 | xsd:integer |
| http://test.org/nonNegativeInteger5 | 5 | xsd:integer |
| http://test.org/unsignedLong5 | 5 | xsd:integer |
| http://test.org/unsignedInt5 | 5 | xsd:integer |
| http://test.org/unsignedShort5 | 5 | xsd:integer |
| http://test.org/positiveInteger5 | 5 | xsd:integer |
Stardog canonicalizes literals by default to improve query and loading performance. If you require literals to be stored exactly as specified, you can set index.literals.canonical=false when creating your database.
Hi Stephen, thanks for clarification. Is it somewhere documented, which datatypes are getting canonicalized? And since which Stardog version is this behavior implemented? We might migrate some databases in order to have a consistent state.
I don't think the list of datatypes is in the docs. We canonicalise integers, decimals, floats, and date/date times. This behaviour has been in place since at least Stardog 1.0 (i.e. 2012).
We generally advise against disabling this option since it could lead to an increase of disk IO and thus adverse effects for both read and write performance. These effects are hard to quantify since it depends on the number of literals with such datatypes in your database. You may want to test your workload on your data before making the decision.
This kind of canonicalization makes sense, but without documentation on which datatypes are mapped to which, it is unacceptable, as it adds uncertainty whenever any process relies on consistent datatypes.
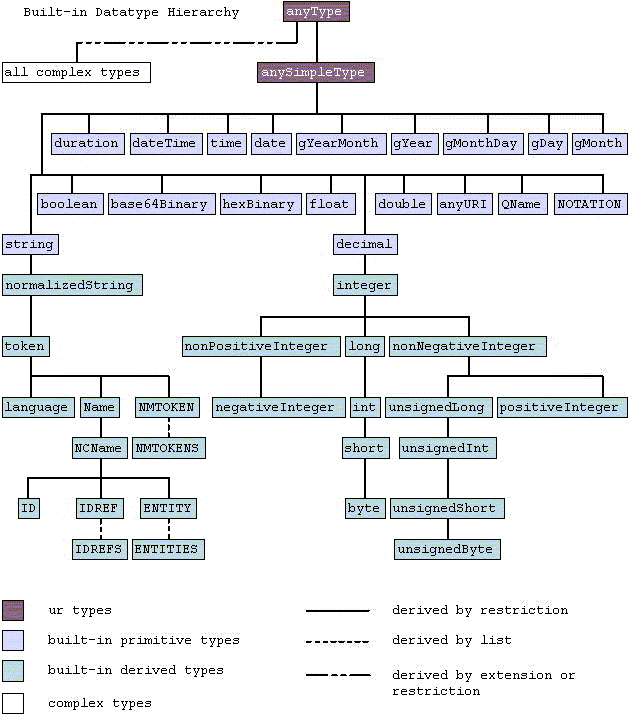
I don't think canonicalisation can introduce any inconsistency within a single database since this setting can only be specified at creation time. The datatype mapping rules are very simple, only sub-types of xsd:integer are not preserved (cf. the XSD datatype hierarchy: https://www.w3.org/TR/xmlschema-2/type-hierarchy.gif). However, values of other datatypes can change their lexical representation, too, while retaining the datatype.
Even though the index.literals.canonical option is set, we have some same values with different datatypes in our graphs, which finally resembles problems. Last time these values suddenly disappeared, might have been due to restarting the database.
I can't say, what exactly happened to these graphs in meantime. But the data somehow persisted in the database and is also getting exported. Is there any plausible way how this can happen?
I'm not sure I understand what your issue is here. I cannot reproduce these results with the data you posted. Are you able to share data that allows us to reproduce the query results you are showing? And what are the results you are expecting to see?
Also, values definitely shouldn't be disappearing from something as minor as a server restart. Could you elaborate more on what's happening there?
{kind=link}